精读——Deep Residual Learning for Image Recognition

有一个反直觉的事情:就是为什么深度越深,网络的表现反而越差呢?ResNet解决的就是这个问题。
Introduction
Is learning better networks as easy as stacking more layers?
传统的答案是,网路很深的时候,会出现梯度消失/梯度爆炸(vanishing gradients / exploding gradients).
在ResNet出现前,通常可以在权重初始化时,不要过大或者过小,同时可以在中间层加入一些normalization layers,使得校验每个层之间的输出、均值和方差。
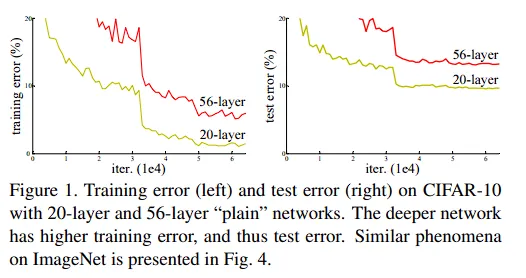
在上图中,可以看到deeper network has higher training error,这不是过拟合(测试误差也很大),这个很反直觉:因为我们至少应该是输入
Deep Residual Learning Framework 的基础理解
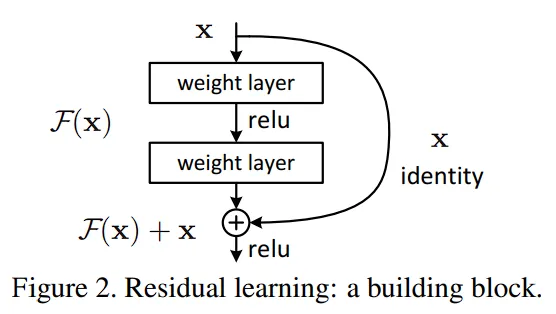
浅的网络输出
这样有两个好处:
- 不会增加模型复杂度,没有额外的参数要学习。
- 计算也不会更复杂,因为只是一个加法而已。
Related-Work
Is learning better networks as easy as stacking more layers?
Residual Network
如何处理输入形状和输出形状不同的情况?
本文提到了两种方法:
- 输入和输出添加额外的0,使得可以相加
- 投影:通过
的卷积层,使得输出通道是输入通道的两倍。
Batch Normalization
目的是使feature map满足均值为1,方差为0的分布规律。
Experiments
- Title: 精读——Deep Residual Learning for Image Recognition
- Author: Skywalker
- Created at : 2025-04-24 14:26:20
- Updated at : 2025-04-28 23:24:26
- Link: https://skywalker.github.io/2025/04/24/《Deep-Residual-Learning-for-Image-Recognition》论文精读/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments